
티스토리 뷰
1. Introduction
ML에 Pycaret이 있다면, DL에는 AutoKeras가 있다.
짧은 몇 일 동안 DL을 처음으로 돌려보고 느낀 점은 정말 hyper parameter optimization이 사람의 손을 정말 많이 탄다는 것이다.
굉장히 많은 optimization algorithm & 설계 변수 (hidden layer, neuron 갯수, activation function, learning rate 등등)이 있고,
그것들이 나온 막락을 이해하려면 족히 1년은 걸릴 것이라고 판단되었다..!
관련 분야로 학위를 받는 대학원생이라면 조금 더 깊이를 채워보겠으나,
지금 나는 내가 풀고자 하는 문제에 바로 응용 접목해서 결과를 도출하고 그 의미를 천천히 이해하면서 깊이를 더해가는 방식을 택했다.
AutoKeras는 DL 분야 연착륙을 도와주는 tool이라고 생각하고, 예제가 잘 나와있어서 이것을 실습해 보는 것을 1탄으로 정했다.
2. Auto Keras
공식 홈페이지: https://autokeras.com/
튜토리얼에 각종 예제가 있다. MNIST셋을 이용한 이미지 분류, 회귀, 언어 처리, 그리고 정형화된 데이터의 분류 및 회귀 등 다양한 예제가 있었다.
다행히도 (?) 내가 하려고 하는 Structured Data Regression에 대한 모델도 예제가 있어서 바로 가져와 보았다.
코드를 한줄한줄 실습해보고 잘 돌아가는지 확인해보았다.
Step 1. 관련 라이브러리 불러오기 및 데이터 준비


Train 사이즈를 정하고, Train과 test로 나뉘는 코드가 들어가있다.
Code 11-12를 살펴보면 해당 파일이 .csv로 저장되는 것을 확인할 수 있다.
CSV 파일을 열어보면 Train은 총 18576개의 데이터 셋트가, Eval에는 총 2064개의 데이터 셋트가 있었다.
(18576 = 2064 x 9)
Step 2. Automated deep learning
놀랍게도 이 다음에 바로 AUTO DL이 실행된다.

reg.fit을 통해 트레인 데이터 파일 경로를 정하고, 예측 하는 컬럼과 이포크 숫자를 지정해준다.
test_file_path를 통해 test 결과가 가장 좋은 셋트를 predicted_y로 뽑아주는 것으로 보인다.
그리고 나서는 그 결과를 print 해준다.
잠깐 짬을 내서 GPU를 얼마나 잡아먹고 있는지 살펴보았다.
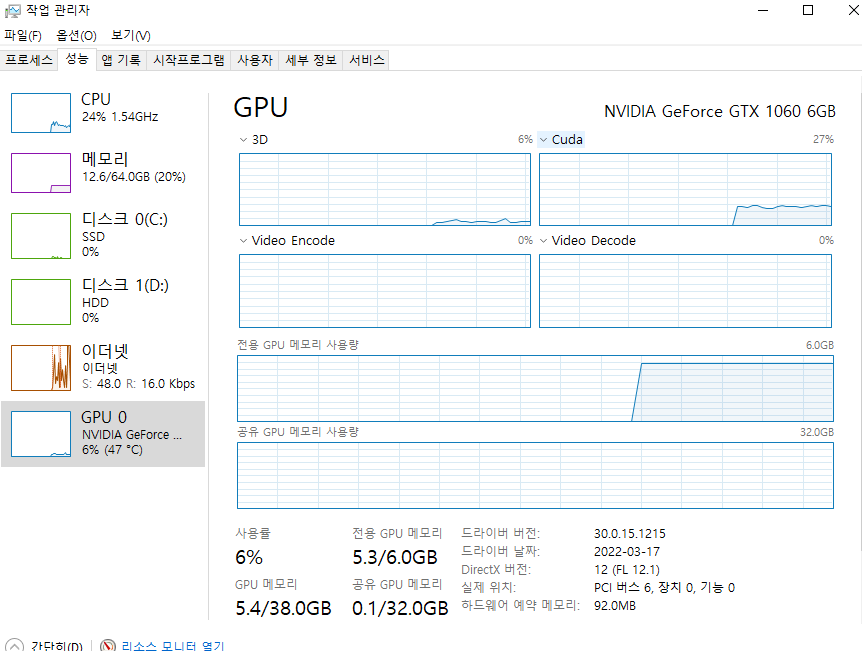

Document에는 타 라이브러리 간의 호환성을 보여주기 위해 작성된 것으로 보인다.
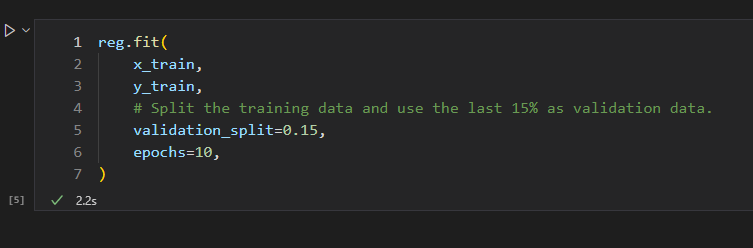
Step 3. Validation
바로 다음스텝인 validation으로 넘어갔다.
Step 4. Summary
마지막으로 Summary를 통해서 DNN 구조가 어떻게 나왔는지 알려준다.
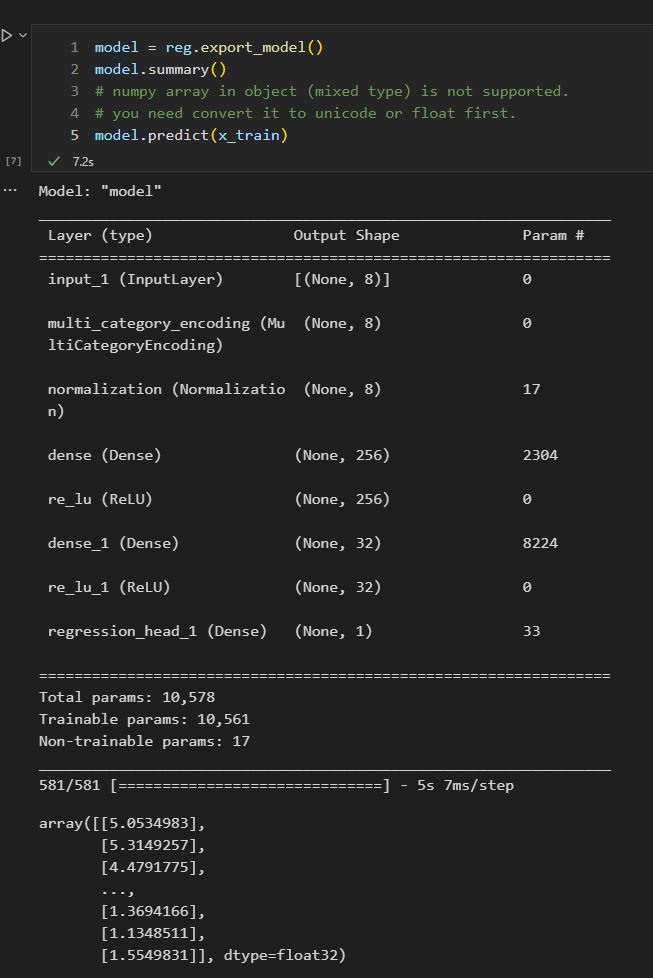
여기까지가 document에서 소개된 코드를 직접 실행해본 내용이다.
한 가지 아쉬운(?)점은 score에 대한 accuracy가 바로 보여졌으면 더 좋았겟다는 생각..
Jupyter Variable에 저장된 총 변수 목록은 다음과 같다.
Training & Validation Score 계산 코드만 추가해서 여러가지를 minor tuning 작업을 거치면 내 문제에 바로 적용할 수 도 있지 않을까?
작은 기대를 끝으로 오늘의 일기 끝 :)
'AI STUDY > Python' 카테고리의 다른 글
| [Python] 22.08.31 딥러닝 실습 (3탄: PINN - DeepXDE) (0) | 2022.08.31 |
|---|---|
| [Python] 22.08.27 딥러닝 실습 (2탄: PINN) (0) | 2022.08.27 |
| [Python] 22.08.15 딥러닝을 위한 텐서플로우/GPU 세팅 (CUDA, cuDNN) (0) | 2022.08.15 |
| [Python] 22.06.05 최적화 패키지 실습 (1탄) (2) | 2022.06.05 |
| [Python] 21.12.11 Pycaret 패키지 실습 (2탄) (0) | 2021.12.11 |
- Total
- Today
- Yesterday
- 포닥 일기
- 연구 일기
- 미국 박사 후 연구원
- 박사 일기
- 공대 조교수
- 박사과정
- 해외포닥
- 해외 포닥
- 박사 후 연구원
- 식물일기
- 라틴어 수업
- 주간리포트
- 국내 포닥
- 틸란드시아
- 포닥 임용
- 공학 박사
- 공학 박사 일기장
- 독후감
- 미국 포닥
- LCA 분석
- 대학원생
- 논문 일기
- 라틴어수업
- 공학박사 일기장
- 포닥 이후 진로
- 포닥 2년차
- 공학박사
- Jinsustory
- 박사일기
- 한동일
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |